Voice Settings give you precise control over how your agent sounds and listens. From speech speed to background ambiance, pronunciation rules to turn-taking — this is where you shape the audio experience.
Location: Left Sidebar → Agent Settings → Voice tab
Select the voice for your agent. Click the dropdown to browse available voices — you can preview each one before selecting.
Control how fast your agent speaks.
Slide left for a more measured, deliberate pace. Slide right for quicker delivery. Find the sweet spot that matches your use case — slower often works better for complex information, faster for simple confirmations.
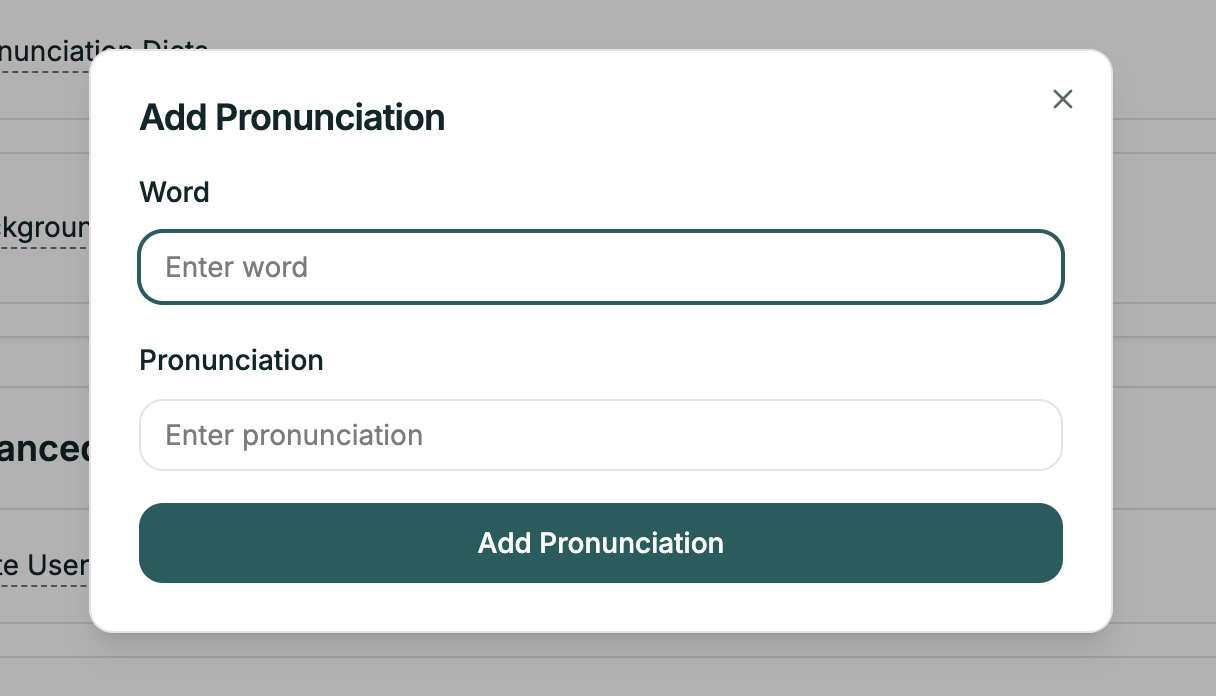
Add custom pronunciations for words that aren’t pronounced correctly by the default voice.
This is especially useful for:
To add a pronunciation: Click Add Pronunciation to open the modal.
Add ambient audio behind your agent’s voice for a more natural feel.
When enabled, the user’s audio is muted until the agent’s first response is complete. Useful for preventing early interruptions during the greeting.
Detects when a call goes to voicemail instead of reaching a live person.
Voicemail detection may not work as expected if Release Time is less than 0.6 seconds.
Automatically redacts sensitive personal information from transcripts and logs.
Filters out background noise and improves voice clarity before processing. This helps reduce false detections caused by environmental sounds — useful when callers are in noisy environments.
Fine-tune how your agent recognizes when someone is speaking.
Minimum probability score to classify audio as speech.
Volume floor below which audio is ignored, even if detected as speech. Filters out quiet background noise that might otherwise be misclassified.
Duration of continuous speech needed before the system registers “user is speaking.” Prevents brief noises (coughs, clicks, background sounds) from triggering speech detection.
Duration of silence needed after speech before the system considers the user done talking. This directly sets the minimum turn-taking latency — lower values make the agent respond faster but risk cutting off the user mid-thought.
Start with defaults. Only adjust these if you’re experiencing specific issues like missed words or premature responses.
Intelligent detection of when the caller is done speaking. When enabled, the agent uses context and speech patterns — not just silence — to determine when it’s time to respond.
This reduces the need to rely solely on Release Time for turn-taking. The model analyzes prosody, sentence completion, and conversational patterns to make smarter decisions about when the user has finished their turn.
When Smart Turn Detection is enabled, this sets the maximum time the agent will wait for additional speech before responding. Acts as an upper bound — the agent may respond sooner if the model detects the user is done.
Cooldown period (in seconds) after the agent starts speaking during which user speech is ignored. Prevents the agent from being cut off prematurely — especially useful when the agent’s first few words overlap with the caller’s audio.
This helps prevent conversation loops when the caller and agent interrupt each other — the agent will wait this duration before allowing itself to be interrupted again.