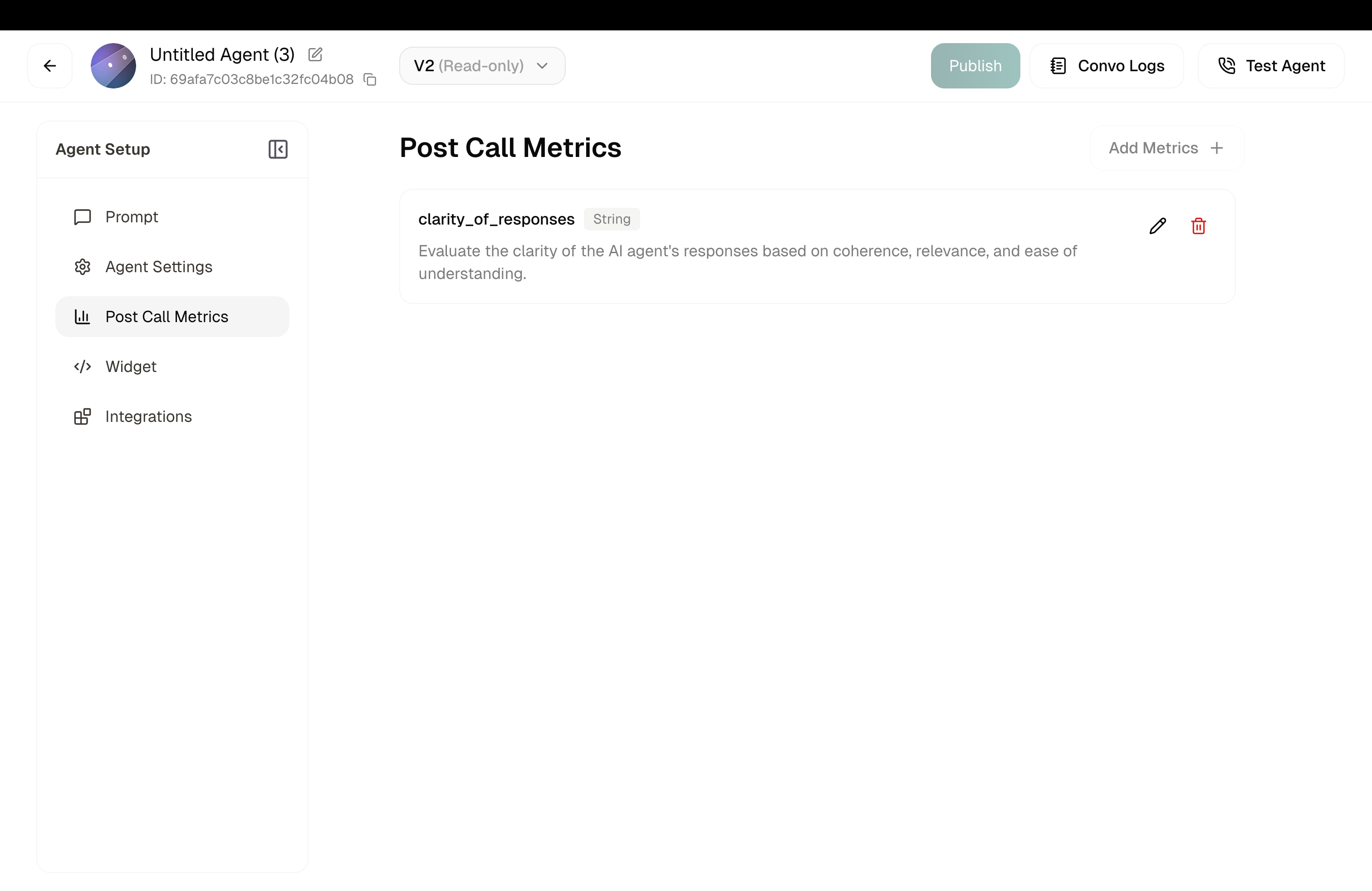
Post-Call Metrics
Post-Call Metrics
Post-call metrics let you pull specific insights from conversations after they end. Define what you want to know — satisfaction scores, call outcomes, issue categories — and Atoms analyzes each call to fill in the answers.
Location: Left Sidebar → Post Call Metrics
How It Works
- You define metrics — What questions do you want answered about each call?
- Call ends — Conversation completes normally
- AI analyzes — Atoms reviews the transcript against your metrics
- Data populated — Your metrics get filled in automatically
- Access anywhere — View in logs, receive via webhook, export
Creating a New Metric
Click the Add Metrics + button to open the configuration panel. You’ll see two options:
Disposition Metrics
Templates
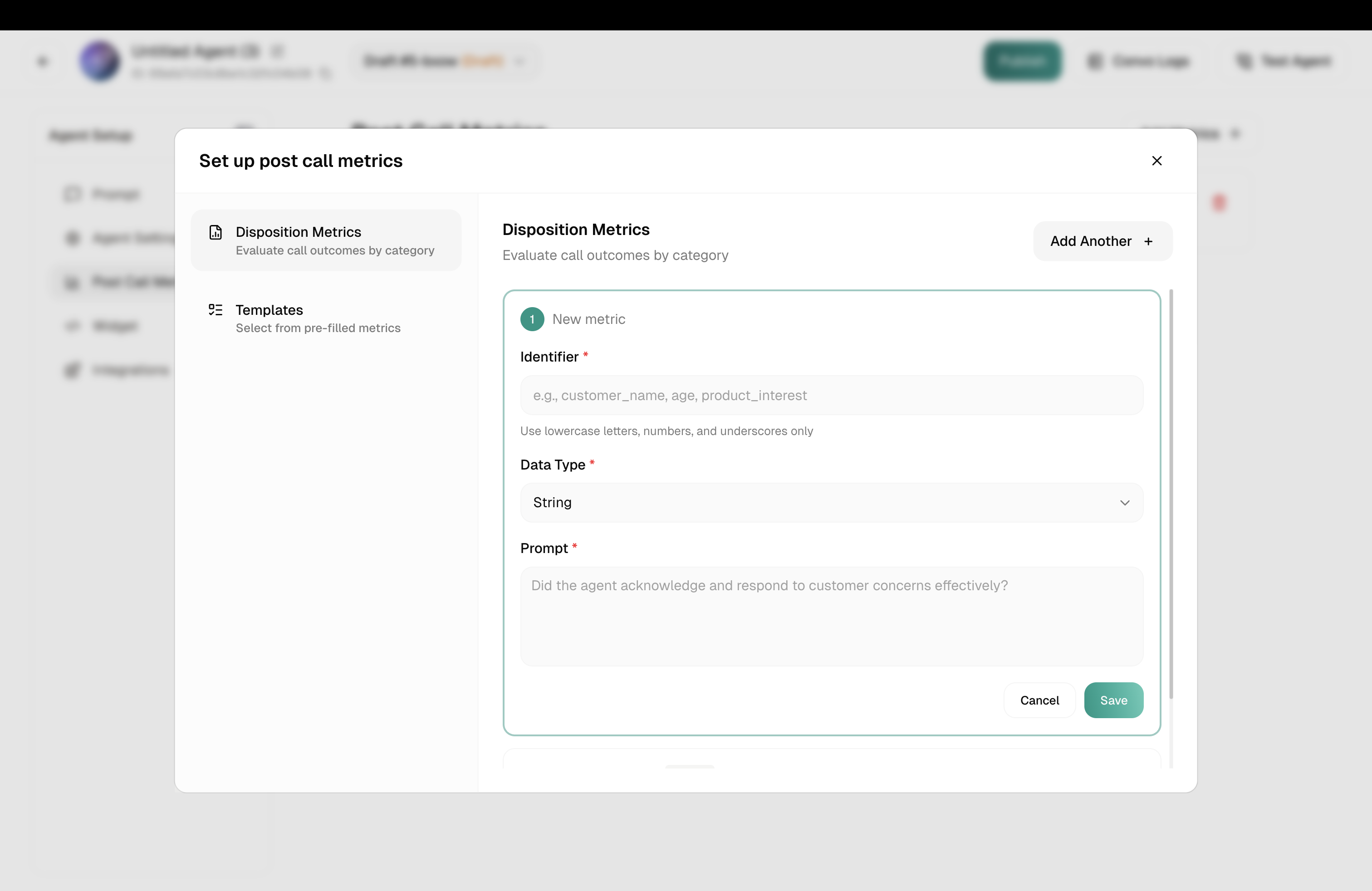
Build a custom metric from scratch. Fill in the Identifier, Data Type, and Prompt — see details below.
Use Add Another + to create multiple metrics at once.
Don’t forget to hit Save in the Disposition tab once you’re done.
Configuring a Metric
Each metric needs three things:
Identifier
This is the key used to reference the metric in exports, webhooks, and the API.
Naming rules: Lowercase letters, numbers, and underscores only. No spaces or special characters.
Data Type
Prompt
This is the question the AI answers by analyzing the transcript. Be specific.
Good prompts:
- “Did the agent acknowledge and respond to customer concerns effectively?”
- “Rate customer satisfaction from 1 to 5 based on tone and words used.”
- “What was the primary reason for this call? Options: billing, technical, account, other”
Vague prompts to avoid:
- “Was it good?”
- “Customer happy?”
Start with 3-5 metrics. Too many can slow analysis and clutter your data. Add more as you learn what insights matter most.
Example Metrics
Call Outcome
Satisfaction Score
Follow-Up Needed
Issue Category
Configuring via API
Post-call metrics are set through the agent versioning flow: edit a draft’s config, publish it as a new version, and activate the version. There is no standalone post-call-analytics endpoint — configuration lives on the agent’s active version.
Full flow
Disposition metric schema
Each entry in dispositionMetrics takes four fields:
Two analytics flags apply globally:
Reading current metrics
The active version’s metrics are surfaced under _resolvedConfig.postCallAnalyticsConfig. Each entry round-trips exactly as sent: identifier, dispositionMetricPrompt, dispositionMetricType, and choices (when the type is ENUM).